
Напишите определения базы данных, типа данных, домена, кортежа, отношения, целостности базы данных. Приведите пример отношения, на котором укажите атрибуты, кортежи, домены, типы данных.
Дайте определение реляционной модели данных и ее аспектам. Перечислите операции реляционной алгебры с примерами.
Напишите определения потенциального ключа и требований, которым он должен удовлетворять. Дайте определения первичному, альтернативному и суррогатному ключу. Приведите примеры отношений с естественным первичным ключом и суррогатным первичным ключом; для каждого из отношений укажите альтернативные ключи.
Перечислите основные числовые, строковые, бинарные, календарные типы данных в PostgreSQL с указанием объема занимаемой памяти и диапазона допустимых значений. Напишите особенности значения NULL.
Для версионирования схемы БД наиболее широко используются следующие подходы: метод генерации на базе исходного кода, метод инкрементальных изменений и метод идемпотентных изменений. Напишите, в чем заключаются эти подходы к версионированию, а также перечислите их плюсы и минусы.
Что называется проектированием баз данных? Укажите его основные задачи. Дайте определение этапам проектирования с указанием последовательности их выполнения. Перечислите возможные при плохом проектировании аномалии БД с примерами.
Что такое нормальная форма? Дайте определения первой, второй, третьей и четвертой нормальным формам. Для каждой НФ приведите пример отношения, которое не удовлетворяет ее условиям, после чего предложите способ приведения данного отношения к этой НФ.
Перечислите возможные виды связи (ссылок друг на друга) между таблицами БД. Приведите примеры для каждого вида связи.
Какие ограничения могут накладываться на таблицы БД? Для каждого ограничения укажите, что оно значит, и приведите пример ситуации, когда оно может быть полезно. Перечислите все возможные действия (action) со значениями аттрибутов-ссылок при обновлении/удалении родительского кортежа.
Перечислите известные вам методы хранения иерархических конструкций. Для каждого из них нарисуйте граф хотя бы из трех уровней, укажите способ обхода; перечислите сильные и слабые стороны.
Перечислите используемые в PostgreSQL подходы для сортировки и регистронезависимого поиска, укажите их слабые стороны.
Перечислите известные вам оконные функции в PostgreSQL с описанием и примерами применения.
Приведите примеры коррелирующего и некоррелируюшего подзапросов. Сколько раз они выполняются? Расположите по скорости выполнения реализации одного и того же запроса с использованием коррелирующего подзапроса, некоррелирующего подзапроса и соединения посредством JOIN. Перечислите известные вам виды JOIN-ов с кратким описанием того, что они делают. На языке SQL с помощью JOIN выразите следующие операции реляционной алгебры над отношениями A и B:
Пересечение (А и В);
Объединение (А или В);
Разность (А без В);
Симметрическая разность ((А или В) без (А и В)).
Дайте определение представления (VIEW). Напишите его основные особенности, преимущества и ограничения. Перечислите, каким условиям должно удовлетворять представление, чтобы быть изменяемым. Приведите пример случая, когда создание представления может быть удобно, и пример кода для создания представления.
Что такое ACID? Дайте опеределение каждому принципу из этой аббревиатуры.
Напишите, в чем заключается журнализация изменений, какие данные содержит журнал транзакций и по какому алгоритму работает журнализация.
Какие преимущества дает MVCC (MultiVersion Concurrency Control) с точки зрения изолированности транзакций? Приведите пошаговые примеры обновления, добавления и удаления данных из таблицы при MVCC.
Перечислите уровни изолированности транзакций и соответствующие каждому из них возможные аномалии (с определением). Для каждой из этих аномалий приведите примеры проблемных транзакций.
Перечислите плюсы и минусы хранимых процедур. Приведите пример команды для создания хранимой процедуры (функции) и пример команды для её вызова. Чем хранимая процедура отличается от триггера?
Напишите алгоритм выполнения распределенной транзакции в PostgreSQL. Перечислите плюсы и минусы распределенных транзакций.
Для чего используются персистентные очереди? Перечислите плюсы и минусы персистентных очередей.
Какие преимущества дает использование индексов? Перечислите известные вам виды индексов в PostgreSQL с описанием их особенностей. Приведите примеры графов индексов для btree и GiST (R-Tree), примеры таблиц для hash-индексов и битовых масок. Какую цену приходится платить за использование индексов?
На примерах запросов покажите, как изменяется стратегия выполнения простого запроса, запроса с условием, запроса с сортировкой после создания индексов.
Что представляет собой протоколирование запросов? На какие запросы надо обращать внимание в первую очередь при протоколировании?
Для чего используется EXPLAIN? Перечислите его особенности и недостатки. Приведите пример. Укажите, на что следует обратить внимание в первую очерель при использовании EXPLAIN. Чем отличаются EXPLAIN и EXPLAIN ANALYZE?
Перечислите плюсы работы с нормализованными таблицами. Дайте определение денормализации. Какие подходы могут использоваться для поддержания денормализованных данных в актуальном состоянии?
Перечислите известные вам частные случаи, когда становится возможна оптимизация DELETE, COUNT, LIMIT. Приведите примеры оптимизированных запросов.
Дайте определение способам организации работы БД при работе с актуальными и историческими данными. Перечислите особенности работы с актуальными и историческими данными.
Что такое секционирование (partitioning)? Напишите особенности секционирования в старых версиях PostgreSQL с использованием наследования или с использованием расширения pg_pathman и в PostgreSQL 10. Приведите пример секционирования таблицы для PostgreSQL 10.
Какие подходы используются для уменьшения времени блокировок при оптимизации на уровне приложения? Как работает оптимистическая блокировка? Приведите примеры оптимистичной и пессимистичной блокировок. Приведите примеры срочного запроса и неблокирующего создания индекса.
Для каких целей может использоваться репликация? Приведите основные варианты взаимодействия серверов при репликации. Перечилите варианты реализации репликации и гарантии репликации. Укажите общие принципы, плюсы и минусы физической и логической репликации в PostgreSQL.
Перечислите этапы предварительной подготовки документов для полнотекстового поиска. Что позволяет делать PostgreSQL при использовании словарей для полнотекстового поиска? Приведите примеры подключения и использования словаря.
Какой пакет необходимо установить для работы с географическими данными в PostgreSQL? Приведите пример запроса для определения расстояния между двумя точками на сфероиде.
Для чего производится резервное копирование? Перечислите особенности логических и физических резервных копий. Укажите плюсы и минусы создания: а.) физической резервной копии с pg_basebackup; б.) логической резервной копии с pg_dump/pg_dumpall. Приведите примеры команд для создания резервных копий этими способами.
Какие файлы содержат настройки конфигурации PostgreSQL и за что отвечает каждый из них? Перечислите основные параметры конфигурации использования памяти в PostgreSQL. Укажиет, какие таблицы PostgreSQL можно посмотреть для мониторинга поведения СУБД (таблица — что по ней можно посмотреть). Перечислите известные вам термины реализации безопасности в СУБД и их функции. Объясните, что такое SQL-injection и приведите пример.
Перечислите ключевые особенности архитектуры MySQL. Укажите типы подсистем хранения в MySQL с их особенностями. Чем интересны реализации DDL и ALTER TABLE в MySQL? Перечислите известные вам режимы репликации в MySQL и основные проблемы реализации репликации в MySQL.
Перечислите общие характеристики, чаще всего присущие NoSQL БД. Укажите плюсы и минусы для нормализованных данных и для данных в виде агрегатов. Приведите пример как некоторая реляционная модель может быть представлена в виде агрегатов.
Перечислите известные вам типы NoSQL БД с их основными особенностями и примерами БД этих типов.
Table of Contents
If you’re preparing for an SQL interview, you’ve got to make sure that you are prepared to handle all sorts of questions, from the basic to the advanced SQL interview questions. A little preparation can go a long way in boosting your confidence for that next Database Developer job interview.
The set of common SQL interview questions here covers all SQL functionalities, split into three sections of basic, intermediate, and advanced difficulty. If you want a refresher you may want to check out SQL Tutorials recommended for you.
But before we hop into these SQL server interview questions, let’s take a look at some general questions on SQL and related interviews.
How Do I Prepare for the SQL Interview?
Like you would prepare for any other interview, though you might find yourself focusing a little more on theory with an SQL interview. Be sure to know the commands, as well as the theory behind processes and decisions. A mix of hands-on learning and reading up is the best way to prepare for an SQL interview.
What Do I Need to Know for the SQL Interview?
You’ll need to know some basic ideas and commands about how to operate with databases. Essentially, you will have to prove that you can carry out the functions you would need to do in a practical setting. Fortunately, the SQL interview questions and answers listed here cover everything you need to know.
How Can I Practice SQL?
The best way to practice SQL is to download the database software and start working with it. That means creating a table, entering data, and modifying it. Look up the various SQL commands and execute them in the software. And of course, don’t forget to read SQL query interview questions.
Top SQL Interview Questions and Answers
Basic SQL Interview Questions
The following section covers basic concepts, with the following section focusing on intermediate and advanced SQL questions.
1. What are the 5 basic SQL commands?
The 5 basic SQL commands are ALTER, UPDATE, DELETE, INSERT and CREATE. Of course, there are many more commands, some more nuanced, but the aforementioned are the fundamentals.
2. What is the difference between DBMS and RDBMS?
A Database Management System (DBMS) is a software application that helps you build and maintain databases. A Relational Database Management System (RDBMS) is a subset of DBMS, and it is one based on the relational model of the DBMS.
3. Can we embed Pl/SQL in SQL? Justify your answers.
PL/SQL is a procedural language, and it has one or more SQL statements in it, so SQL can be embedded in a PL/SQL block; however, PL/SQL cannot be embedded in SQL as SQL executes a single query at a time.
DECLARE /* this is a PL/SQL block */
qty_on_hand NUMBER(5);
BEGIN
SELECT quantity INTO qty_on_hand FROM inventory /* this is the SQL statement embedded in the PL/SQL block */
WHERE product = 'TENNIS RACKET';
END;4. What do you mean by Data Manipulation Language (DML)?
Data Manipulation Language (DML) includes the most common SQL statements to store, modify, delete, and retrieve data. They are SELECT, UPDATE, INSERT, and DELETE.
DECLARE /* this is a PL/SQL block */
qty_on_hand NUMBER(5);
BEGIN
SELECT quantity INTO qty_on_hand FROM inventory /* this is the SQL statement embedded in the PL/SQL block */
WHERE product = 'TENNIS RACKET';
END;5. What is a join in SQL? What are the types of joins?
A join is used to query data from multiple tables based on the relationship between the fields.
There are four types of joins:
Inner Join
Rows are returned when there is at least one match of rows between the tables.
select first_name, last_name, order_date, order_amount
from customers c
inner join orders o
on c.customer_id = o.customer_id/* customers and orders are two tables. Data will be displayed from the two tables where the customer_id from customer table matches
The customer_id from the orders table. */
Right Join
Right join returns all rows from the right table and those which are shared between the tables. If there are no matching rows in the left table, it will still return all the rows from the right table.
select first_name, last_name, order_date, order_amount
from customers c
left join orders o
on c.customer_id = o.customer_id/* customers and orders are two tables. All rows from the Orders table is returned with matching rows from the Customers table if any */
Left Join
Left join returns all rows from the Left table and those which are shared between the tables. If there are no matching rows in the right table, it will still return all the rows from the left table.
select first_name, last_name, order_date, order_amount
from customers c
left join orders o
on c.customer_id = o.customer_id/* customers and orders are two tables. All rows from the customers table is returned with matching rows from the orders table if any */
Full Join
Full join return rows when there are matching rows in any one of the tables. This means it returns all the rows from the left-hand side table and all the rows from the right-hand side table.
select first_name, last_name, order_date, order_amount
from customers c
full join orders o
on c.customer_id = o.customer_id/* customers and orders are two tables. All rows from the Orders table and customer table are returned */
6. What is the difference between the CHAR and VARCHAR2 datatype in SQL?
CHAR is used to store fixed-length character strings, and VARCHAR2 is used to store variable-length character strings.
For example, suppose you store the string ‘Database’ in a CHAR(20) field and a VARCHAR2(20) field.
The CHAR field will use 22 bytes (2 bytes for leading length).
The VARCHAR2 field will use 10 bytes only (8 for the string, 2 bytes for leading length).
7. Explain SQL constraints.
Constraints are used to specify the rules of data type in a table. They can be specified while creating and altering the table. The following are the constraints in SQL:
- NOT NULL: Restricts NULL value from being inserted into a column
- CHECK: Verifies that all values in a field satisfy a condition
- DEFAULT: Automatically assigns a default value if no value has been specified for the field
- UNIQUE: Ensures unique values to be inserted into the field
- INDEX: Indexes a field providing faster retrieval of records
- PRIMARY KEY: Uniquely identifies each record in a table
- FOREIGN KEY: Ensures referential integrity for a record in another table
8. What is a primary key, a foreign key, and a unique key?
Primary Key
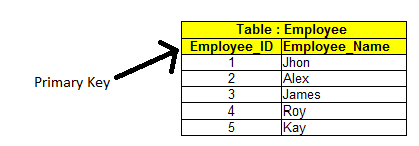
The primary key is a field in the table which uniquely identifies a row. It cannot be NULL
Foreign Key
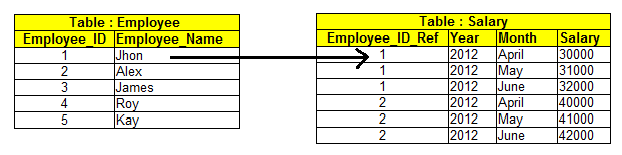
A foreign key is a field in one table that is a primary key in another table. A relationship is created between the two tables by referencing the foreign key of one table with the primary key of another table.
In the example below, the employee_id_ref in the salary table is the foreign key.
Unique Key
The Unique Key uniquely identifies a record in a table. There can be many unique key constraints defined on a table.
|
EMP_ID |
EMP_NAME |
Government_ID |
|
222 |
Harry |
111-203-987 |
|
333 |
Stephan |
789-456-123 |
|
444 |
Lan |
745-562-321 |
In the table above Emp_id is the primary key but Government_id is the unique key. You may want the Government_id to be unique for every employee. Since the data belongs to the government, you may not want it to be the primary key.
The Complete SQL Bootcamp 2023: Go from Zero to Hero
9. What is a trigger?
Triggers are stored programs that get automatically executed when an event such as INSERT, DELETE, and the UPDATE (DML) statement occurs. Triggers can also be evoked in response to Data definition statements(DDL) and database operations, for example, SERVER ERROR, LOGON.
create trigger dbtrigger
on database
for
create_table,alter_table,drop_table
as
print'you can not create ,drop and alter table in this database'
rollback;
create trigger emptrigger
on emp
for
insert,update,delete
as
print'you can not insert,update and delete this table i'
rollback;10. What is the difference between SQL and MySQL?
SQL is a structured query language used to access the DBMS whereas MYSQL is an Open Source Relational DBMS. The latter operates on the relational model, allowing for more advanced ways to deal with data.
11. What is a NULL Value field?
A NULL value is a field with No Value.
Intermediate-Level Interview Questions
12. What are ACID properties in a transaction?
In order to maintain consistency in a database’s ‘before and after’ transactions, certain properties are followed. They are:
- Atomicity: The transaction must happen fully and cannot be left midway
- Consistency: This maintains integrity constraints to ensure valid data enters the database
- Isolation: Controls concurrency
- Durability: Once a transaction is committed, it remains committed
13. What is Dateadd in SQL?
Dateadd is a function that is used to add a number to a specified part of the date and returns the modified date. The syntax is DATEADD (date_part, value, input_date).
The Date part can take any of the following forms:
|
date_part |
abbreviations |
|
Year |
yy, yyyy |
|
Quarter |
qq, q |
|
Month |
Mm, m |
|
dayofyear |
dy, y |
|
Day |
dd, d |
|
Week |
wk, ww |
|
Hour |
hh |
|
Minute |
mi, n |
|
Second |
ss, s |
|
Millisecond |
ms |
|
Microsecond |
mcs |
|
Nanosecond |
ns |
14. What is SAVEPOINT in transaction control?
A SAVEPOINT is a point in a transaction when you can roll the transaction back to a certain point without rolling back the entire transaction.
SQL> SAVEPOINT A
SQL> INSERT INTO TEST VALUES (1,'Savepoint A');1 row inserted.
SQL> SAVEPOINT B
SQL> INSERT INTO TEST VALUES (2,'Savepoint B');1 row inserted.
SQL> ROLLBACK TO B;Rollback complete.
SQL> SELECT * FROM TEST;
ID MSG
-------- -----------
1 Savepoint A15. What is a Natural Join?
SELECT * FROM COUNTRIES NATURAL JOIN CITIES
SELECT * FROM COUNTRIES JOIN CITIES
USING (COUNTRY, COUNTRY_ISO_CODE)A natural join by default is an inner join that creates an implicit join based on the common columns in the two tables being joined:
A NATURAL JOIN can be an INNER join, a LEFT OUTER join, or a RIGHT OUTER join. The default is INNER join.
If the tables COUNTRIES and CITIES have two common columns named COUNTRY and COUNTRY_ISO_CODE, the following two SELECT statements are equivalent:
16. What is a Cross Join?
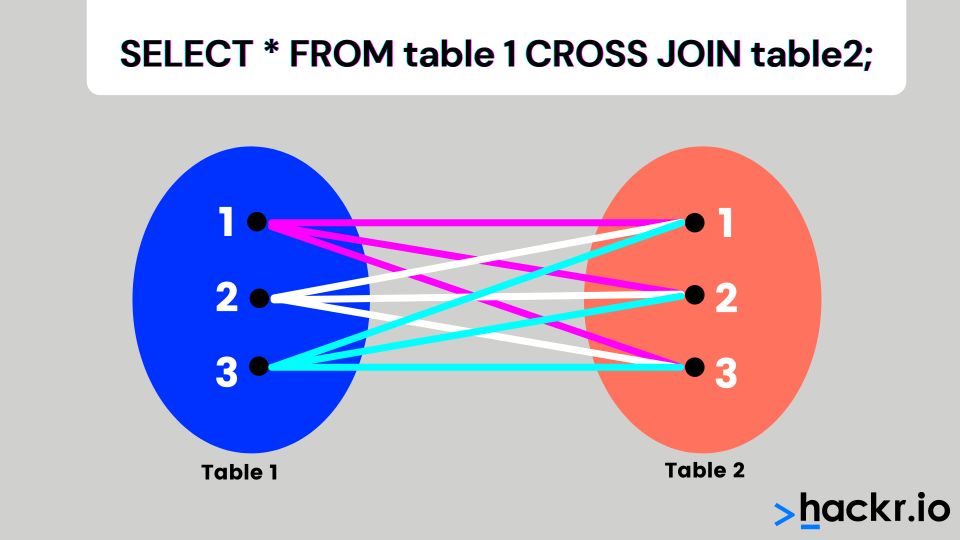
In an SQL cross join, a combination of every row from the two tables is included in the result set. This is also called cross-product join.
For example, if table A has ten rows and table B has 20 rows, the result set will have 10 * 20 = 200 rows provided there is a NOWHERE clause in the SQL statement.
17. What are the subsets of SQL?
The following are the subsets of SQL
- DDL(Data Definition Language): Includes SQL commands like CREATE, ALTER, and DELETE
- DML(Data Manipulation Language): Accesses and manipulates data, including the INSERT and UPDATE commands
- DCL(Data Control Language): Controls access to the database. Uses commands like GRANT and REVOKE.
18. What are scalar functions in SQL?
Scalar Functions are used to return a single value based on the input values. Scalar Functions are as follows:
- UCASE(): Converts the specified field in upper case
SELECT UCASE("SQL Tutorial is FUN!") AS UppercaseText;
UppercaseText
SQL TUTORIAL IS FUN!- LCASE(): Converts the specified field in lower case
19. What is a cursor, and when do you use it?
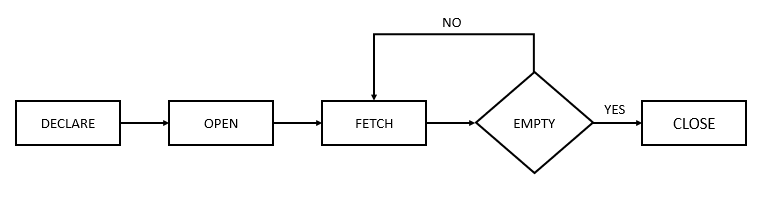
A cursor is a database object which is used to manipulate data by traversing row by row in a result set. A cursor is used when you need to retrieve data, one row at a time from a result set and when you need to update records one row at a time.
DECLARE @CustomerId INT
,@Name VARCHAR(100)
,@Country VARCHAR(100)
--DECLARE AND SET COUNTER.
DECLARE @Counter INT
SET @Counter = 1
--DECLARE THE CURSOR FOR A QUERY.
DECLARE PrintCustomers CURSOR READ_ONLY
FOR
SELECT CustomerId, Name, Country
FROM Customers
--OPEN CURSOR.
OPEN PrintCustomers
--FETCH THE RECORD INTO THE VARIABLES.
FETCH NEXT FROM PrintCustomers INTO
@CustomerId, @Name, @Country
--LOOP UNTIL RECORDS ARE AVAILABLE.
WHILE @@FETCH_STATUS = 0
BEGIN
IF @Counter = 1
BEGIN
PRINT 'CustomerID' + CHAR(9) + 'Name' + CHAR(9) + CHAR(9) + CHAR(9) + 'Country'
PRINT '------------------------------------'
END
--PRINT CURRENT RECORD. PRINT CAST(@CustomerId AS VARCHAR(10)) + CHAR(9) + CHAR(9) + CHAR(9) + @Name + CHAR(9) + @Country
--INCREMENT COUNTER.
SET @Counter = @Counter + 1
--FETCH THE NEXT RECORD INTO THE VARIABLES.
FETCH NEXT FROM PrintCustomers INTO
@CustomerId, @Name, @Country
END
--CLOSE THE CURSOR.
CLOSE PrintCustomers
DEALLOCATE PrintCustomers20. What is a set-based solution?
Cursors operate on individual rows, and in the case of a set, it works on a resultant set of data, which could be a table/view or a join of both. The resultant set is an output of a SQL query.
21. What is a forward cursor?
Forward cursors support fetching of rows from start to end from a result set. You cannot go to the previous row in the result set.
22. State one situation where set-based solutions are better than cursor-based solutions.
Set-based solutions provide better performance when you are working on a result set, as opposed to one row at a time. They are concise and more readable.
23. What is normalization and what are the normal forms?
Normalization is a process in database design to minimize data redundancy and dependency. The database is divided into two or more tables, and relationships are defined between them.
First Normal Form
Every record is unique in a table and is identified by a primary or a composite key.
StudiD Name Phonenum
————————
1 John 9176612345,9176645698
2 Susie 9176645789
3 Jim 9176696325
In the above table the field ‘phonenum’ is a multi-valued attribute, so it is not in 1NF.
The table below is in 1NF as there is no multi-valued attribute.
StudiD Name Phonenum
——————
1 John 9176612345
1 John 9176645698
2 Susie 9176645789
3 Jim 9176696325
Second Normal Form
The table must be in First Normal Form, and it should have a single column as its primary key. 2NF tries to reduce the redundant data getting stored in memory. To transform the table above into 2NF, we split the table into two tables:
StudiD Name /* student table */
- John
2 Susie
- Jim
StudiD Phonenum /* studentphonenumber table */
——————
1 9176612345
1 9176645698
2 9176645789
3 9176696325
Third Normal Form
The table must be in Second Normal Form and must have no transitive functional dependencies, i.e., a non-key column must not be dependent on another non-key column within the same table.
Consider the EMPLOYEE_DETAIL table: This table is not in the third normal form because the fields emp_state and emp_city depend on emp_zip and not on the primary key emp_id.
|
EMP_ID |
EMP_NAME |
EMP_ZIP |
EMP_STATE |
EMP_CITY |
|
222 |
Harry |
201010 |
CT |
Monro |
|
333 |
Stephan |
02228 |
TX |
Dallas |
|
444 |
Lan |
060007 |
IL |
Chicago |
The table above is split into 2 tables and now the tables are in the third normal form.
EMPLOYEE table:
|
EMP_ID |
EMP_NAME |
EMP_ZIP |
|
222 |
Harry |
201010 |
|
333 |
Stephan |
02228 |
|
444 |
Lan |
060007 |
EMPLOYEE_ZIP table:
|
EMP_ZIP |
EMP_STATE |
EMP_CITY |
|
201010 |
CT |
Monro |
|
02228 |
TX |
Dallas |
|
060007 |
IL |
Chicago |
24. What is denormalization and when do you use it?
Denormalization is a technique used to improve performance so the table design allows you to avoid complex joins with redundant data. If the application involves heavy read operations, then denormalization is used at the expense of the write operations performance.
25. What are clustered indexes and non-clustered indexes?
A table can have only one clustered index. In this type of index, it reorders the table based on the key values and physically stores them in that order.
The non-clustered index does not have the physical ordering of the data in the table; it has a logical order.
CREATE CLUSTERED INDEX IX_tblStudent_Gender_Score
ON student(gender ASC, total_score DESC)The script above creates a clustered index named “IX_tblStudent_Gender_Score” on the student table. This index is created on the “gender” and “total_score” columns. An index that is created on more than one column is called the “composite index”.
A non-clustered index doesn’t sort the physical data inside the table. A non-clustered index is stored in one place, and table data is stored in another place. This allows for more than one non-clustered index per table.
CREATE NONCLUSTERED INDEX IX_tblStudent_Name
ON student(name ASC)The script above creates a non-clustered index on the “name” column of the student table — the index sorts by name in ascending order. The table data and index will be stored in different places.
26. What is T-SQL?
It is an extension of SQL (Structured Query Language) developed by Sybase and used by Microsoft.
27. What are system functions? Offer an example.
System functions are operations performed on the database server, and values are returned accordingly. Example @@ERROR — Returns 0 if the previous Transact-SQL statement encountered no errors. Otherwise, it returns an error number.
@@ERROR — Returns 0 if the previous Transact-SQL statement encountered no errors.
28. What is a transaction log?
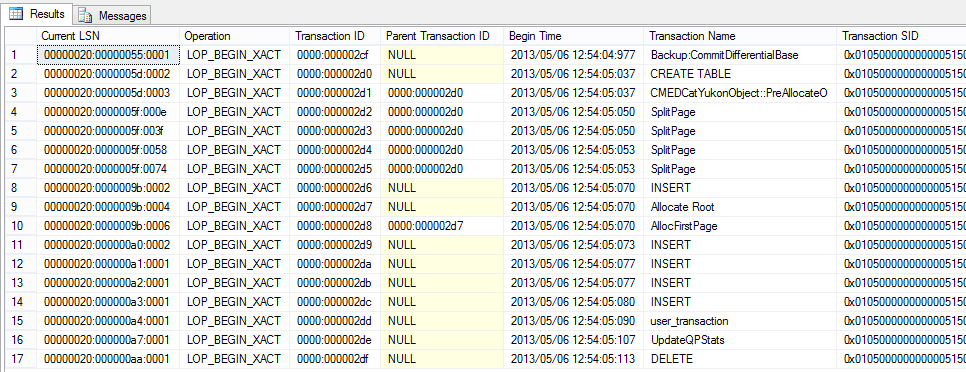
A log is an audit trail file where the history of actions executed by the DBMS is stored.
29. How do you maintain database integrity when deletions from one table automatically cause deletions in another?
ON DELETE CASCADE is a command that is used when deletions happen in the parent table, and all child records are automatically deleted, and the child table is referenced by the foreign key in the parent table.
CREATE TABLE products
( product_id INT PRIMARY KEY,
product_name VARCHAR(50) NOT NULL,
category VARCHAR(25)
);
CREATE TABLE inventory
( inventory_id INT PRIMARY KEY,
product_id INT NOT NULL,
quantity INT,
min_level INT,
max_level INT,
CONSTRAINT fk_inv_product_id
FOREIGN KEY (product_id)
REFERENCES products (product_id)
ON DELETE CASCADE
);The Products table is the parent table and the inventory table is the child table. If a productid is deleted from the parent table all the inventory records for that productid will be deleted from the child table
30. Can we use TRUNCATE with a WHERE clause?
No, we cannot use TRUNCATE with the WHERE clause.
31. Define COMMIT.
When a COMMIT is used in a transaction, all changes made are written into the database permanently.
BEGIN TRANSACTION;
DELETE FROM HumanResources.JobCandidate
WHERE JobCandidateID = 13;
COMMIT TRANSACTION; The example above deletes a job candidate in an SQL server.
32. What does CHECK CONSTRAINT do?
Check Constraint limits the values that can enter a column in a database table. It is used as an integrity constraint check.
The following SQL creates a CHECK constraint on the «Age» column when the «Persons» table is created. The CHECK constraint ensures that you can not have any person below 18 years:
The syntax below is in MySQL.
CREATE TABLE Persons (
ID int NOT NULL,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Age int,
CHECK (Age>=18)
);33. What is a schema?
A schema is a collection of database objects in a database for a particular user/owner. Objects can be tables, views, indices, and so on.
34. How can you create an empty table from an existing table?
CREATE TABLE NEW_TABLE_NAME AS SELECT [column1, column2 ……column]
FROM EXISTING_TABLE_NAME [WHERE ]35. What is a composite key?
When more than one column is used to define the primary key, it is called a composite key. Here is a SQL syntax to create a composite key in MySQL:
CREATE TABLE SAMPLE_TABLE
(COL1 integer,
COL2 varchar(30),
COL3 varchar(50),
PRIMARY KEY (COL1, COL2)); 36. How do you sort records in a table?
The ORDER BY Clause is used to sort records in a table.
SELECT * FROM Emp ORDER BY salary; By default, the records are returned in ascending order.
37. What is a shared lock?
When two transactions are granted read access to the same data, they are given a shared lock. This enables reading the same data, and data is not updated until the shared lock is released.
38. What is a deadlock?
A deadlock is a situation where two or more transactions are waiting indefinitely for each other to release the locks.
The following is an example of a deadlock situation:
39. What is lock escalation?
Lock escalation is the process of converting row or page locks into table locks. It is an optimization technique used by RDBMS like SQL Server dynamically.
40. What is SQL injection?
SQL injection is a code injection technique used to hack data-driven applications.
41. What are views, and why are they used?
SQL views are virtual tables created from one or more tables. Views are a subset of data; hence, it can limit the degree of exposure of data from the tables.
The following SQL creates a view that shows all customers from Brazil:
CREATE VIEW Brazil_Customers_view AS
SELECT CustomerName, ContactName
FROM Customers
WHERE Country = "Brazil";You can query the view above as follows:
SELECT * FROM Brazil_Customers_view;42. How do we avoid getting duplicate entries in a query?
The Select DISTINCT is used to get distinct data from tables using a query.
The following SQL statement selects only the DISTINCT values from the «Country» column in the «Customers» table:
SELECT DISTINCT Country FROM Customers;43. Give an example of a comparison operator in SQL.
EQUAL TO written as = is used to compare data values
44. What is a Subquery?
A subQuery is a SQL query nested into a larger Query.
SELECT
employee_id, first_name, last_name
FROM
employees
WHERE
department_id IN (SELECT
department_id
FROM
departments
WHERE
location_id = 1700)
ORDER BY first_name , last_name;The query placed within the parentheses is called a subquery. It is also known as an inner query or inner select. The query that contains the subquery is called an outer query or an outer select.
A non-correlated subquery is an independent query, and the output of the subquery is substituted in the main query.
Advanced SQL Interview Questions and Answers
46. What is a SYSTEM Privilege?
This is when rights are given to a user, usually by the DBA, to perform a particular action on the database schema objects like creating tablespaces.
The following are examples of system privileges that can be granted to users:
- CREATE TABLE allows a grantee to create tables in the grantee’s schema
- CREATE USER allows a grantee to create users in the database
- CREATE SESSION allows a grantee to connect to an Oracle database to create a user session
47. What are Object Privileges?
An object-level privilege is a permission granted to a database user account or role to perform some action on a database object. These object privileges include SELECT, INSERT, UPDATE, DELETE, ALTER, INDEX on tables, and so on.
The following examples are object privileges that can be granted to users:
- SELECT ON hr.employees TO myuser
- INSERT ON hr.employees TO myuser
48. What does the BCP command do?
The BCP (Bulk Copy) is a utility or a tool that exports/imports data from a table into a file and vice versa.
49. What does the VARIANCE function do?
This function returns the VARIANCE of a set of numbers:
CREATE TABLE EMP (EMPNO NUMBER(4) NOT NULL,
ENAME VARCHAR2(10),
JOB VARCHAR2(9),
SAL NUMBER(7, 2),
DEPTNO NUMBER(2));
INSERT INTO EMP VALUES (1, 'SMITH', 'CLERK', 800, 20);
INSERT INTO EMP VALUES (2, 'ALLEN', 'SALESMAN', 1600, 30);
INSERT INTO EMP VALUES (3, 'WARD', 'SALESMAN', 1250, 30);
INSERT INTO EMP VALUES (4, 'JONES', 'MANAGER', 2975, 20);
INSERT INTO EMP VALUES (5, 'MARTIN','SALESMAN', 1250, 30);
INSERT INTO EMP VALUES (6, 'BLAKE', 'MANAGER', 2850, 30);
INSERT INTO EMP VALUES (7, 'CLARK', 'MANAGER', 2850, 10);
INSERT INTO EMP VALUES (8, 'SCOTT', 'ANALYST', 3000, 20);
INSERT INTO EMP VALUES (9, 'KING', 'PRESIDENT',3000, 10);
INSERT INTO EMP VALUES (10,'TURNER','SALESMAN', 1500, 30);
INSERT INTO EMP VALUES (11,'ADAMS', 'CLERK', 1500, 20);
SQL> SELECT VARIANCE(sal)
2 FROM emp;
VARIANCE(SAL)
-------------
759056.81850. What is the role of GRANT and REVOKE commands?
The GRANT command enables privileges on the database objects and the REVOKE command removes them. They are DCL commands.
GRANT CREATE ANY TABLE TO username
GRANT sysdba TO username
GRANT DROP ANY TABLE TO username
REVOKE CREATE TABLE FROM username51. What is a UNION operator?
The UNION operator combines the results of two or more SELECT statements by removing duplicate rows. The columns and the data types must be the same in the SELECT statements.
SELECT City FROM Customers
UNION
SELECT City FROM Suppliers
ORDER BY City;52. Where are stored procedures stored and can we call one inside another?
Stored Procedures are stored in the Data Dictionary of the database.
Yes, we can call a stored procedure from another stored procedure. For example, Procedure2 is the procedure which is called Procedure1. Both Procedure1 and Procedure2 can have business logic implemented in it.
Create PROCEDURE Procedure1
AS BEGIN
Exec Procedure2
END53. Does the data stored in the stored procedure increase access time or execution time?
Data stored in stored procedures can be retrieved much faster than the data stored in the SQL database. Data can be precompiled and stored in stored procedures. This reduces the time gap between query and compiling as the data has been pre-compiled and stored in the procedure. Procedures may or may not return values.
54. Can a view be active if the base table is dropped?
No, the view cannot be active if the parent table is dropped.
55. What is a One-Many Relationship in SQL?
In a One-Many relationship, a record in one table can be associated or related to many records in another table.
56. Distinguish between a table and a field in SQL.
The collection of data organized in the form of columns and rows refers to the table. The number of columns in a table refers to the field.
Table: Employee_Details
Fields: Emp_id, Emp_name, Emp_dept, Emp_salary
57. What is data integrity?
Data integrity defines the accuracy, consistency, and reliability of data that is stored in the database.
There are four kinds of data integrity:
- Row integrity
- Column integrity
- Referential integrity
- User-defined integrity
58. What are entities and relationships?
- Entity: A person, place, or any real-world thing that can be represented as a table is called an entity. An example is an employee table that represents the details of an employee in an organization.
- Relationship: Relationship defines the dependency that entities share amongst each other. An example is the fact that an employee name, ID, salary might belong to the same or different tables.
59. How do TRUNCATE and DELETE Differ?
|
DELETE |
TRUNCATE |
|
DML command |
DDL command |
|
Can use WHERE |
Cannot use WHERE |
|
Deletes one row from the table |
Deletes all rows from the table |
|
Rollback possible |
No rollback |
60. What is the difference between null, zero, and blank space?
NULL refers to a value that is unknown, not available, inapplicable, or unassigned. Zero is a number, and blank space is treated as a character.
61. Which function is used to return the remainder in a division operator in SQL?
The MOD function returns the remainder in the division operation.
62. What are case manipulation functions?
Case manipulation functions convert existing data in the table to lower, upper or mixed case characters.
63. What are the different case manipulation functions in SQL?
- LOWER: Converts all the characters to lowercase
- UPPER: Converts all the characters to uppercase
- INITCAP: Converts initial character of each word to uppercase
64. What are the different character manipulation functions?
- CONCAT: Joins two or more string values
- SUBSTR: Extracts string of a specific length
- LENGTH: Returns the length of the string
- INSTR: Returns the position of the specific character
- LPAD: Padding of the left-side character value for right-justified value
- RPAD: Padding of right-side character value for left-justified value
- TRIM: Removes the defined character from beginning and end or both
- REPLACE: Replaces a specific sequence of characters with another sequence of characters
65. Define inconsistent dependency.
The difficulty of accessing data as the path may be broken or missing defines inconsistent dependency. Inconsistent dependency enables users to search for data in the wrong different table which afterward results in an error as an output.
66. What are GROUP functions? Why do we need them?
Group functions work on a set of rows and return a single result per group. The popularly used group functions are AVG, MAX, MIN, SUM, VARIANCE, COUNT
67. Distinguish between BETWEEN and IN conditional operators.
BETWEEN displays the rows based on a range of values. IN checks for values contained in a specific set of values.
Example:
SELECT * FROM Students where ROLL_NO BETWEEN 10 AND 50;
SELECT * FROM students where ROLL_NO IN (8,15,25);68. What is the MERGE statement?
The statement enables conditional updates or inserts into the table. It updates the row if it exists or inserts the row if it does not exist.
69. Explain the recursive stored procedure.
A stored procedure calling itself until it reaches some boundary condition is a recursive stored procedure. It enables the programmers to use a set of code any number of times.
70. How can dynamic SQL be executed?
It can be executed in the following ways:
- By executing the query with parameters.
- By using EXEC
- By using sp_executesql
71. What is the stored procedure?
It is a function consisting of many SQL statements to access the database system. Several SQL statements are consolidated into a stored procedure and are executed wherever and whenever required.
72. What is auto increment?
This keyword allows a new unique number to be generated whenever a new record is inserted into the table. It can be used wherever we need the PRIMARY KEY.
73. What is a data warehouse?
Data from multiple sources of information is stored in a central repository called the data warehouse. Data warehouses have subsets of data called data marts. The data stored is transformed and used for online mining and processing.
74. What are user-defined functions?
Functions written to use the specific logic whenever required are user-defined functions. It avoids redundancy by avoiding writing the same logic again.
75. What is the ALIAS command?
This command provides another name to a table or a column. It can be used in the WHERE clause of a SQL query using the as keyword.
Example:
SELECT S.StudentID, E.Result from student S, Exam as E where S.StudentID = E.StudentIDS and E are alias names for student table and exam table respectively.
76. What is Collation?
Collation is defined as the set of rules that determines how to store and compare data.
77. Mention the different types of collation sensitivity.
The following are the types of collation sensitivity:
- Case
- Kana
- Width
- Accent
78. What are STUFF and REPLACE functions?
STUFF: Overwrites the existing character or inserts a string into another string. The syntax is:
STUFF(string_expression,start, length, replacement_characters)REPLACE: replaces the existing characters of all the occurrences. The syntax is:
REPLACE (string_expression, search_string, replacement_string)Start Preparing With These SQL Interview Questions
With the help of this list of the top SQL interview questions, you will stand a better chance of nailing interviews for Database Administrator and SQL developer positions.
It will even help with an SQL server certification. You could also use the SQL in 10 Minutes, Sams Teach Yourself book to help prepare.
SQL Interview Questions/Answers PDF
Good luck! And don’t forget, on top of reading SQL questions for interviews, you have to practice hands-on.
People are also reading:
- SQL Courses
- SQL Certifications
- SQL Books
- Download SQL Cheat Sheet PDF
- Top DBMS Interview Questions & Answers
- Difference between MongoDB and MySQL
- Create a Database in MySQL
- Difference between OLTP and OLAP
- What is MongoDB?
- Basic SQL Commands
Table of Contents
If you’re preparing for an SQL interview, you’ve got to make sure that you are prepared to handle all sorts of questions, from the basic to the advanced SQL interview questions. A little preparation can go a long way in boosting your confidence for that next Database Developer job interview.
The set of common SQL interview questions here covers all SQL functionalities, split into three sections of basic, intermediate, and advanced difficulty. If you want a refresher you may want to check out SQL Tutorials recommended for you.
But before we hop into these SQL server interview questions, let’s take a look at some general questions on SQL and related interviews.
How Do I Prepare for the SQL Interview?
Like you would prepare for any other interview, though you might find yourself focusing a little more on theory with an SQL interview. Be sure to know the commands, as well as the theory behind processes and decisions. A mix of hands-on learning and reading up is the best way to prepare for an SQL interview.
What Do I Need to Know for the SQL Interview?
You’ll need to know some basic ideas and commands about how to operate with databases. Essentially, you will have to prove that you can carry out the functions you would need to do in a practical setting. Fortunately, the SQL interview questions and answers listed here cover everything you need to know.
How Can I Practice SQL?
The best way to practice SQL is to download the database software and start working with it. That means creating a table, entering data, and modifying it. Look up the various SQL commands and execute them in the software. And of course, don’t forget to read SQL query interview questions.
Top SQL Interview Questions and Answers
Basic SQL Interview Questions
The following section covers basic concepts, with the following section focusing on intermediate and advanced SQL questions.
1. What are the 5 basic SQL commands?
The 5 basic SQL commands are ALTER, UPDATE, DELETE, INSERT and CREATE. Of course, there are many more commands, some more nuanced, but the aforementioned are the fundamentals.
2. What is the difference between DBMS and RDBMS?
A Database Management System (DBMS) is a software application that helps you build and maintain databases. A Relational Database Management System (RDBMS) is a subset of DBMS, and it is one based on the relational model of the DBMS.
3. Can we embed Pl/SQL in SQL? Justify your answers.
PL/SQL is a procedural language, and it has one or more SQL statements in it, so SQL can be embedded in a PL/SQL block; however, PL/SQL cannot be embedded in SQL as SQL executes a single query at a time.
DECLARE /* this is a PL/SQL block */
qty_on_hand NUMBER(5);
BEGIN
SELECT quantity INTO qty_on_hand FROM inventory /* this is the SQL statement embedded in the PL/SQL block */
WHERE product = 'TENNIS RACKET';
END;4. What do you mean by Data Manipulation Language (DML)?
Data Manipulation Language (DML) includes the most common SQL statements to store, modify, delete, and retrieve data. They are SELECT, UPDATE, INSERT, and DELETE.
DECLARE /* this is a PL/SQL block */
qty_on_hand NUMBER(5);
BEGIN
SELECT quantity INTO qty_on_hand FROM inventory /* this is the SQL statement embedded in the PL/SQL block */
WHERE product = 'TENNIS RACKET';
END;5. What is a join in SQL? What are the types of joins?
A join is used to query data from multiple tables based on the relationship between the fields.
There are four types of joins:
Inner Join
Rows are returned when there is at least one match of rows between the tables.
select first_name, last_name, order_date, order_amount
from customers c
inner join orders o
on c.customer_id = o.customer_id/* customers and orders are two tables. Data will be displayed from the two tables where the customer_id from customer table matches
The customer_id from the orders table. */
Right Join
Right join returns all rows from the right table and those which are shared between the tables. If there are no matching rows in the left table, it will still return all the rows from the right table.
select first_name, last_name, order_date, order_amount
from customers c
left join orders o
on c.customer_id = o.customer_id/* customers and orders are two tables. All rows from the Orders table is returned with matching rows from the Customers table if any */
Left Join
Left join returns all rows from the Left table and those which are shared between the tables. If there are no matching rows in the right table, it will still return all the rows from the left table.
select first_name, last_name, order_date, order_amount
from customers c
left join orders o
on c.customer_id = o.customer_id/* customers and orders are two tables. All rows from the customers table is returned with matching rows from the orders table if any */
Full Join
Full join return rows when there are matching rows in any one of the tables. This means it returns all the rows from the left-hand side table and all the rows from the right-hand side table.
select first_name, last_name, order_date, order_amount
from customers c
full join orders o
on c.customer_id = o.customer_id/* customers and orders are two tables. All rows from the Orders table and customer table are returned */
6. What is the difference between the CHAR and VARCHAR2 datatype in SQL?
CHAR is used to store fixed-length character strings, and VARCHAR2 is used to store variable-length character strings.
For example, suppose you store the string ‘Database’ in a CHAR(20) field and a VARCHAR2(20) field.
The CHAR field will use 22 bytes (2 bytes for leading length).
The VARCHAR2 field will use 10 bytes only (8 for the string, 2 bytes for leading length).
7. Explain SQL constraints.
Constraints are used to specify the rules of data type in a table. They can be specified while creating and altering the table. The following are the constraints in SQL:
- NOT NULL: Restricts NULL value from being inserted into a column
- CHECK: Verifies that all values in a field satisfy a condition
- DEFAULT: Automatically assigns a default value if no value has been specified for the field
- UNIQUE: Ensures unique values to be inserted into the field
- INDEX: Indexes a field providing faster retrieval of records
- PRIMARY KEY: Uniquely identifies each record in a table
- FOREIGN KEY: Ensures referential integrity for a record in another table
8. What is a primary key, a foreign key, and a unique key?
Primary Key
The primary key is a field in the table which uniquely identifies a row. It cannot be NULL
Foreign Key
A foreign key is a field in one table that is a primary key in another table. A relationship is created between the two tables by referencing the foreign key of one table with the primary key of another table.
In the example below, the employee_id_ref in the salary table is the foreign key.
Unique Key
The Unique Key uniquely identifies a record in a table. There can be many unique key constraints defined on a table.
|
EMP_ID |
EMP_NAME |
Government_ID |
|
222 |
Harry |
111-203-987 |
|
333 |
Stephan |
789-456-123 |
|
444 |
Lan |
745-562-321 |
In the table above Emp_id is the primary key but Government_id is the unique key. You may want the Government_id to be unique for every employee. Since the data belongs to the government, you may not want it to be the primary key.
The Complete SQL Bootcamp 2023: Go from Zero to Hero
9. What is a trigger?
Triggers are stored programs that get automatically executed when an event such as INSERT, DELETE, and the UPDATE (DML) statement occurs. Triggers can also be evoked in response to Data definition statements(DDL) and database operations, for example, SERVER ERROR, LOGON.
create trigger dbtrigger
on database
for
create_table,alter_table,drop_table
as
print'you can not create ,drop and alter table in this database'
rollback;
create trigger emptrigger
on emp
for
insert,update,delete
as
print'you can not insert,update and delete this table i'
rollback;10. What is the difference between SQL and MySQL?
SQL is a structured query language used to access the DBMS whereas MYSQL is an Open Source Relational DBMS. The latter operates on the relational model, allowing for more advanced ways to deal with data.
11. What is a NULL Value field?
A NULL value is a field with No Value.
Intermediate-Level Interview Questions
12. What are ACID properties in a transaction?
In order to maintain consistency in a database’s ‘before and after’ transactions, certain properties are followed. They are:
- Atomicity: The transaction must happen fully and cannot be left midway
- Consistency: This maintains integrity constraints to ensure valid data enters the database
- Isolation: Controls concurrency
- Durability: Once a transaction is committed, it remains committed
13. What is Dateadd in SQL?
Dateadd is a function that is used to add a number to a specified part of the date and returns the modified date. The syntax is DATEADD (date_part, value, input_date).
The Date part can take any of the following forms:
|
date_part |
abbreviations |
|
Year |
yy, yyyy |
|
Quarter |
qq, q |
|
Month |
Mm, m |
|
dayofyear |
dy, y |
|
Day |
dd, d |
|
Week |
wk, ww |
|
Hour |
hh |
|
Minute |
mi, n |
|
Second |
ss, s |
|
Millisecond |
ms |
|
Microsecond |
mcs |
|
Nanosecond |
ns |
14. What is SAVEPOINT in transaction control?
A SAVEPOINT is a point in a transaction when you can roll the transaction back to a certain point without rolling back the entire transaction.
SQL> SAVEPOINT A
SQL> INSERT INTO TEST VALUES (1,'Savepoint A');1 row inserted.
SQL> SAVEPOINT B
SQL> INSERT INTO TEST VALUES (2,'Savepoint B');1 row inserted.
SQL> ROLLBACK TO B;Rollback complete.
SQL> SELECT * FROM TEST;
ID MSG
-------- -----------
1 Savepoint A15. What is a Natural Join?
SELECT * FROM COUNTRIES NATURAL JOIN CITIES
SELECT * FROM COUNTRIES JOIN CITIES
USING (COUNTRY, COUNTRY_ISO_CODE)A natural join by default is an inner join that creates an implicit join based on the common columns in the two tables being joined:
A NATURAL JOIN can be an INNER join, a LEFT OUTER join, or a RIGHT OUTER join. The default is INNER join.
If the tables COUNTRIES and CITIES have two common columns named COUNTRY and COUNTRY_ISO_CODE, the following two SELECT statements are equivalent:
16. What is a Cross Join?
In an SQL cross join, a combination of every row from the two tables is included in the result set. This is also called cross-product join.
For example, if table A has ten rows and table B has 20 rows, the result set will have 10 * 20 = 200 rows provided there is a NOWHERE clause in the SQL statement.
17. What are the subsets of SQL?
The following are the subsets of SQL
- DDL(Data Definition Language): Includes SQL commands like CREATE, ALTER, and DELETE
- DML(Data Manipulation Language): Accesses and manipulates data, including the INSERT and UPDATE commands
- DCL(Data Control Language): Controls access to the database. Uses commands like GRANT and REVOKE.
18. What are scalar functions in SQL?
Scalar Functions are used to return a single value based on the input values. Scalar Functions are as follows:
- UCASE(): Converts the specified field in upper case
SELECT UCASE("SQL Tutorial is FUN!") AS UppercaseText;
UppercaseText
SQL TUTORIAL IS FUN!- LCASE(): Converts the specified field in lower case
19. What is a cursor, and when do you use it?
A cursor is a database object which is used to manipulate data by traversing row by row in a result set. A cursor is used when you need to retrieve data, one row at a time from a result set and when you need to update records one row at a time.
DECLARE @CustomerId INT
,@Name VARCHAR(100)
,@Country VARCHAR(100)
--DECLARE AND SET COUNTER.
DECLARE @Counter INT
SET @Counter = 1
--DECLARE THE CURSOR FOR A QUERY.
DECLARE PrintCustomers CURSOR READ_ONLY
FOR
SELECT CustomerId, Name, Country
FROM Customers
--OPEN CURSOR.
OPEN PrintCustomers
--FETCH THE RECORD INTO THE VARIABLES.
FETCH NEXT FROM PrintCustomers INTO
@CustomerId, @Name, @Country
--LOOP UNTIL RECORDS ARE AVAILABLE.
WHILE @@FETCH_STATUS = 0
BEGIN
IF @Counter = 1
BEGIN
PRINT 'CustomerID' + CHAR(9) + 'Name' + CHAR(9) + CHAR(9) + CHAR(9) + 'Country'
PRINT '------------------------------------'
END
--PRINT CURRENT RECORD. PRINT CAST(@CustomerId AS VARCHAR(10)) + CHAR(9) + CHAR(9) + CHAR(9) + @Name + CHAR(9) + @Country
--INCREMENT COUNTER.
SET @Counter = @Counter + 1
--FETCH THE NEXT RECORD INTO THE VARIABLES.
FETCH NEXT FROM PrintCustomers INTO
@CustomerId, @Name, @Country
END
--CLOSE THE CURSOR.
CLOSE PrintCustomers
DEALLOCATE PrintCustomers20. What is a set-based solution?
Cursors operate on individual rows, and in the case of a set, it works on a resultant set of data, which could be a table/view or a join of both. The resultant set is an output of a SQL query.
21. What is a forward cursor?
Forward cursors support fetching of rows from start to end from a result set. You cannot go to the previous row in the result set.
22. State one situation where set-based solutions are better than cursor-based solutions.
Set-based solutions provide better performance when you are working on a result set, as opposed to one row at a time. They are concise and more readable.
23. What is normalization and what are the normal forms?
Normalization is a process in database design to minimize data redundancy and dependency. The database is divided into two or more tables, and relationships are defined between them.
First Normal Form
Every record is unique in a table and is identified by a primary or a composite key.
StudiD Name Phonenum
————————
1 John 9176612345,9176645698
2 Susie 9176645789
3 Jim 9176696325
In the above table the field ‘phonenum’ is a multi-valued attribute, so it is not in 1NF.
The table below is in 1NF as there is no multi-valued attribute.
StudiD Name Phonenum
——————
1 John 9176612345
1 John 9176645698
2 Susie 9176645789
3 Jim 9176696325
Second Normal Form
The table must be in First Normal Form, and it should have a single column as its primary key. 2NF tries to reduce the redundant data getting stored in memory. To transform the table above into 2NF, we split the table into two tables:
StudiD Name /* student table */
- John
2 Susie
- Jim
StudiD Phonenum /* studentphonenumber table */
——————
1 9176612345
1 9176645698
2 9176645789
3 9176696325
Third Normal Form
The table must be in Second Normal Form and must have no transitive functional dependencies, i.e., a non-key column must not be dependent on another non-key column within the same table.
Consider the EMPLOYEE_DETAIL table: This table is not in the third normal form because the fields emp_state and emp_city depend on emp_zip and not on the primary key emp_id.
|
EMP_ID |
EMP_NAME |
EMP_ZIP |
EMP_STATE |
EMP_CITY |
|
222 |
Harry |
201010 |
CT |
Monro |
|
333 |
Stephan |
02228 |
TX |
Dallas |
|
444 |
Lan |
060007 |
IL |
Chicago |
The table above is split into 2 tables and now the tables are in the third normal form.
EMPLOYEE table:
|
EMP_ID |
EMP_NAME |
EMP_ZIP |
|
222 |
Harry |
201010 |
|
333 |
Stephan |
02228 |
|
444 |
Lan |
060007 |
EMPLOYEE_ZIP table:
|
EMP_ZIP |
EMP_STATE |
EMP_CITY |
|
201010 |
CT |
Monro |
|
02228 |
TX |
Dallas |
|
060007 |
IL |
Chicago |
24. What is denormalization and when do you use it?
Denormalization is a technique used to improve performance so the table design allows you to avoid complex joins with redundant data. If the application involves heavy read operations, then denormalization is used at the expense of the write operations performance.
25. What are clustered indexes and non-clustered indexes?
A table can have only one clustered index. In this type of index, it reorders the table based on the key values and physically stores them in that order.
The non-clustered index does not have the physical ordering of the data in the table; it has a logical order.
CREATE CLUSTERED INDEX IX_tblStudent_Gender_Score
ON student(gender ASC, total_score DESC)The script above creates a clustered index named “IX_tblStudent_Gender_Score” on the student table. This index is created on the “gender” and “total_score” columns. An index that is created on more than one column is called the “composite index”.
A non-clustered index doesn’t sort the physical data inside the table. A non-clustered index is stored in one place, and table data is stored in another place. This allows for more than one non-clustered index per table.
CREATE NONCLUSTERED INDEX IX_tblStudent_Name
ON student(name ASC)The script above creates a non-clustered index on the “name” column of the student table — the index sorts by name in ascending order. The table data and index will be stored in different places.
26. What is T-SQL?
It is an extension of SQL (Structured Query Language) developed by Sybase and used by Microsoft.
27. What are system functions? Offer an example.
System functions are operations performed on the database server, and values are returned accordingly. Example @@ERROR — Returns 0 if the previous Transact-SQL statement encountered no errors. Otherwise, it returns an error number.
@@ERROR — Returns 0 if the previous Transact-SQL statement encountered no errors.
28. What is a transaction log?
A log is an audit trail file where the history of actions executed by the DBMS is stored.
29. How do you maintain database integrity when deletions from one table automatically cause deletions in another?
ON DELETE CASCADE is a command that is used when deletions happen in the parent table, and all child records are automatically deleted, and the child table is referenced by the foreign key in the parent table.
CREATE TABLE products
( product_id INT PRIMARY KEY,
product_name VARCHAR(50) NOT NULL,
category VARCHAR(25)
);
CREATE TABLE inventory
( inventory_id INT PRIMARY KEY,
product_id INT NOT NULL,
quantity INT,
min_level INT,
max_level INT,
CONSTRAINT fk_inv_product_id
FOREIGN KEY (product_id)
REFERENCES products (product_id)
ON DELETE CASCADE
);The Products table is the parent table and the inventory table is the child table. If a productid is deleted from the parent table all the inventory records for that productid will be deleted from the child table
30. Can we use TRUNCATE with a WHERE clause?
No, we cannot use TRUNCATE with the WHERE clause.
31. Define COMMIT.
When a COMMIT is used in a transaction, all changes made are written into the database permanently.
BEGIN TRANSACTION;
DELETE FROM HumanResources.JobCandidate
WHERE JobCandidateID = 13;
COMMIT TRANSACTION; The example above deletes a job candidate in an SQL server.
32. What does CHECK CONSTRAINT do?
Check Constraint limits the values that can enter a column in a database table. It is used as an integrity constraint check.
The following SQL creates a CHECK constraint on the «Age» column when the «Persons» table is created. The CHECK constraint ensures that you can not have any person below 18 years:
The syntax below is in MySQL.
CREATE TABLE Persons (
ID int NOT NULL,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Age int,
CHECK (Age>=18)
);33. What is a schema?
A schema is a collection of database objects in a database for a particular user/owner. Objects can be tables, views, indices, and so on.
34. How can you create an empty table from an existing table?
CREATE TABLE NEW_TABLE_NAME AS SELECT [column1, column2 ……column]
FROM EXISTING_TABLE_NAME [WHERE ]35. What is a composite key?
When more than one column is used to define the primary key, it is called a composite key. Here is a SQL syntax to create a composite key in MySQL:
CREATE TABLE SAMPLE_TABLE
(COL1 integer,
COL2 varchar(30),
COL3 varchar(50),
PRIMARY KEY (COL1, COL2)); 36. How do you sort records in a table?
The ORDER BY Clause is used to sort records in a table.
SELECT * FROM Emp ORDER BY salary; By default, the records are returned in ascending order.
37. What is a shared lock?
When two transactions are granted read access to the same data, they are given a shared lock. This enables reading the same data, and data is not updated until the shared lock is released.
38. What is a deadlock?
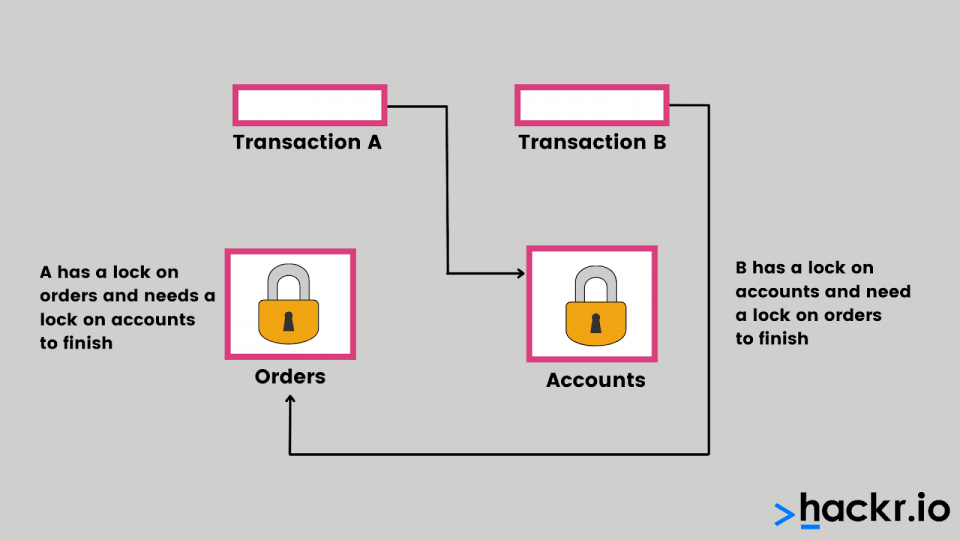
A deadlock is a situation where two or more transactions are waiting indefinitely for each other to release the locks.
The following is an example of a deadlock situation:
39. What is lock escalation?
Lock escalation is the process of converting row or page locks into table locks. It is an optimization technique used by RDBMS like SQL Server dynamically.
40. What is SQL injection?
SQL injection is a code injection technique used to hack data-driven applications.
41. What are views, and why are they used?
SQL views are virtual tables created from one or more tables. Views are a subset of data; hence, it can limit the degree of exposure of data from the tables.
The following SQL creates a view that shows all customers from Brazil:
CREATE VIEW Brazil_Customers_view AS
SELECT CustomerName, ContactName
FROM Customers
WHERE Country = "Brazil";You can query the view above as follows:
SELECT * FROM Brazil_Customers_view;42. How do we avoid getting duplicate entries in a query?
The Select DISTINCT is used to get distinct data from tables using a query.
The following SQL statement selects only the DISTINCT values from the «Country» column in the «Customers» table:
SELECT DISTINCT Country FROM Customers;43. Give an example of a comparison operator in SQL.
EQUAL TO written as = is used to compare data values
44. What is a Subquery?
A subQuery is a SQL query nested into a larger Query.
SELECT
employee_id, first_name, last_name
FROM
employees
WHERE
department_id IN (SELECT
department_id
FROM
departments
WHERE
location_id = 1700)
ORDER BY first_name , last_name;The query placed within the parentheses is called a subquery. It is also known as an inner query or inner select. The query that contains the subquery is called an outer query or an outer select.
A non-correlated subquery is an independent query, and the output of the subquery is substituted in the main query.
Advanced SQL Interview Questions and Answers
46. What is a SYSTEM Privilege?
This is when rights are given to a user, usually by the DBA, to perform a particular action on the database schema objects like creating tablespaces.
The following are examples of system privileges that can be granted to users:
- CREATE TABLE allows a grantee to create tables in the grantee’s schema
- CREATE USER allows a grantee to create users in the database
- CREATE SESSION allows a grantee to connect to an Oracle database to create a user session
47. What are Object Privileges?
An object-level privilege is a permission granted to a database user account or role to perform some action on a database object. These object privileges include SELECT, INSERT, UPDATE, DELETE, ALTER, INDEX on tables, and so on.
The following examples are object privileges that can be granted to users:
- SELECT ON hr.employees TO myuser
- INSERT ON hr.employees TO myuser
48. What does the BCP command do?
The BCP (Bulk Copy) is a utility or a tool that exports/imports data from a table into a file and vice versa.
49. What does the VARIANCE function do?
This function returns the VARIANCE of a set of numbers:
CREATE TABLE EMP (EMPNO NUMBER(4) NOT NULL,
ENAME VARCHAR2(10),
JOB VARCHAR2(9),
SAL NUMBER(7, 2),
DEPTNO NUMBER(2));
INSERT INTO EMP VALUES (1, 'SMITH', 'CLERK', 800, 20);
INSERT INTO EMP VALUES (2, 'ALLEN', 'SALESMAN', 1600, 30);
INSERT INTO EMP VALUES (3, 'WARD', 'SALESMAN', 1250, 30);
INSERT INTO EMP VALUES (4, 'JONES', 'MANAGER', 2975, 20);
INSERT INTO EMP VALUES (5, 'MARTIN','SALESMAN', 1250, 30);
INSERT INTO EMP VALUES (6, 'BLAKE', 'MANAGER', 2850, 30);
INSERT INTO EMP VALUES (7, 'CLARK', 'MANAGER', 2850, 10);
INSERT INTO EMP VALUES (8, 'SCOTT', 'ANALYST', 3000, 20);
INSERT INTO EMP VALUES (9, 'KING', 'PRESIDENT',3000, 10);
INSERT INTO EMP VALUES (10,'TURNER','SALESMAN', 1500, 30);
INSERT INTO EMP VALUES (11,'ADAMS', 'CLERK', 1500, 20);
SQL> SELECT VARIANCE(sal)
2 FROM emp;
VARIANCE(SAL)
-------------
759056.81850. What is the role of GRANT and REVOKE commands?
The GRANT command enables privileges on the database objects and the REVOKE command removes them. They are DCL commands.
GRANT CREATE ANY TABLE TO username
GRANT sysdba TO username
GRANT DROP ANY TABLE TO username
REVOKE CREATE TABLE FROM username51. What is a UNION operator?
The UNION operator combines the results of two or more SELECT statements by removing duplicate rows. The columns and the data types must be the same in the SELECT statements.
SELECT City FROM Customers
UNION
SELECT City FROM Suppliers
ORDER BY City;52. Where are stored procedures stored and can we call one inside another?
Stored Procedures are stored in the Data Dictionary of the database.
Yes, we can call a stored procedure from another stored procedure. For example, Procedure2 is the procedure which is called Procedure1. Both Procedure1 and Procedure2 can have business logic implemented in it.
Create PROCEDURE Procedure1
AS BEGIN
Exec Procedure2
END53. Does the data stored in the stored procedure increase access time or execution time?
Data stored in stored procedures can be retrieved much faster than the data stored in the SQL database. Data can be precompiled and stored in stored procedures. This reduces the time gap between query and compiling as the data has been pre-compiled and stored in the procedure. Procedures may or may not return values.
54. Can a view be active if the base table is dropped?
No, the view cannot be active if the parent table is dropped.
55. What is a One-Many Relationship in SQL?
In a One-Many relationship, a record in one table can be associated or related to many records in another table.
56. Distinguish between a table and a field in SQL.
The collection of data organized in the form of columns and rows refers to the table. The number of columns in a table refers to the field.
Table: Employee_Details
Fields: Emp_id, Emp_name, Emp_dept, Emp_salary
57. What is data integrity?
Data integrity defines the accuracy, consistency, and reliability of data that is stored in the database.
There are four kinds of data integrity:
- Row integrity
- Column integrity
- Referential integrity
- User-defined integrity
58. What are entities and relationships?
- Entity: A person, place, or any real-world thing that can be represented as a table is called an entity. An example is an employee table that represents the details of an employee in an organization.
- Relationship: Relationship defines the dependency that entities share amongst each other. An example is the fact that an employee name, ID, salary might belong to the same or different tables.
59. How do TRUNCATE and DELETE Differ?
|
DELETE |
TRUNCATE |
|
DML command |
DDL command |
|
Can use WHERE |
Cannot use WHERE |
|
Deletes one row from the table |
Deletes all rows from the table |
|
Rollback possible |
No rollback |
60. What is the difference between null, zero, and blank space?
NULL refers to a value that is unknown, not available, inapplicable, or unassigned. Zero is a number, and blank space is treated as a character.
61. Which function is used to return the remainder in a division operator in SQL?
The MOD function returns the remainder in the division operation.
62. What are case manipulation functions?
Case manipulation functions convert existing data in the table to lower, upper or mixed case characters.
63. What are the different case manipulation functions in SQL?
- LOWER: Converts all the characters to lowercase
- UPPER: Converts all the characters to uppercase
- INITCAP: Converts initial character of each word to uppercase
64. What are the different character manipulation functions?
- CONCAT: Joins two or more string values
- SUBSTR: Extracts string of a specific length
- LENGTH: Returns the length of the string
- INSTR: Returns the position of the specific character
- LPAD: Padding of the left-side character value for right-justified value
- RPAD: Padding of right-side character value for left-justified value
- TRIM: Removes the defined character from beginning and end or both
- REPLACE: Replaces a specific sequence of characters with another sequence of characters
65. Define inconsistent dependency.
The difficulty of accessing data as the path may be broken or missing defines inconsistent dependency. Inconsistent dependency enables users to search for data in the wrong different table which afterward results in an error as an output.
66. What are GROUP functions? Why do we need them?
Group functions work on a set of rows and return a single result per group. The popularly used group functions are AVG, MAX, MIN, SUM, VARIANCE, COUNT
67. Distinguish between BETWEEN and IN conditional operators.
BETWEEN displays the rows based on a range of values. IN checks for values contained in a specific set of values.
Example:
SELECT * FROM Students where ROLL_NO BETWEEN 10 AND 50;
SELECT * FROM students where ROLL_NO IN (8,15,25);68. What is the MERGE statement?
The statement enables conditional updates or inserts into the table. It updates the row if it exists or inserts the row if it does not exist.
69. Explain the recursive stored procedure.
A stored procedure calling itself until it reaches some boundary condition is a recursive stored procedure. It enables the programmers to use a set of code any number of times.
70. How can dynamic SQL be executed?
It can be executed in the following ways:
- By executing the query with parameters.
- By using EXEC
- By using sp_executesql
71. What is the stored procedure?
It is a function consisting of many SQL statements to access the database system. Several SQL statements are consolidated into a stored procedure and are executed wherever and whenever required.
72. What is auto increment?
This keyword allows a new unique number to be generated whenever a new record is inserted into the table. It can be used wherever we need the PRIMARY KEY.
73. What is a data warehouse?
Data from multiple sources of information is stored in a central repository called the data warehouse. Data warehouses have subsets of data called data marts. The data stored is transformed and used for online mining and processing.
74. What are user-defined functions?
Functions written to use the specific logic whenever required are user-defined functions. It avoids redundancy by avoiding writing the same logic again.
75. What is the ALIAS command?
This command provides another name to a table or a column. It can be used in the WHERE clause of a SQL query using the as keyword.
Example:
SELECT S.StudentID, E.Result from student S, Exam as E where S.StudentID = E.StudentIDS and E are alias names for student table and exam table respectively.
76. What is Collation?
Collation is defined as the set of rules that determines how to store and compare data.
77. Mention the different types of collation sensitivity.
The following are the types of collation sensitivity:
- Case
- Kana
- Width
- Accent
78. What are STUFF and REPLACE functions?
STUFF: Overwrites the existing character or inserts a string into another string. The syntax is:
STUFF(string_expression,start, length, replacement_characters)REPLACE: replaces the existing characters of all the occurrences. The syntax is:
REPLACE (string_expression, search_string, replacement_string)Start Preparing With These SQL Interview Questions
With the help of this list of the top SQL interview questions, you will stand a better chance of nailing interviews for Database Administrator and SQL developer positions.
It will even help with an SQL server certification. You could also use the SQL in 10 Minutes, Sams Teach Yourself book to help prepare.
SQL Interview Questions/Answers PDF
Good luck! And don’t forget, on top of reading SQL questions for interviews, you have to practice hands-on.
People are also reading:
- SQL Courses
- SQL Certifications
- SQL Books
- Download SQL Cheat Sheet PDF
- Top DBMS Interview Questions & Answers
- Difference between MongoDB and MySQL
- Create a Database in MySQL
- Difference between OLTP and OLAP
- What is MongoDB?
- Basic SQL Commands
Вы готовитесь к собеседованию по SQL для анализ данных? Тогда вы пришли в нужное место!
Это руководство поможет вам усовершенствовать свои навыки работы с SQL, вернуть уверенность в себе и быть готовым к работе!
Здесь вы найдёте подборку реальных вопросов для собеседований, задаваемых в таких компаниях, как Google, Oracle, Amazon, Microsoft и т.д. К каждому вопросу прилагается идеально написанный ответ, что экономит ваше время на подготовку к собеседованию.
Здесь также рассматриваются практические задачи, которые помогут вам понять основные концепции SQL.
@sqlhub – анализ данных с sql.
Мы разделили эту статью на следующие разделы:
- Вопросы для собеседования по SQL
- Вопросы для собеседования по PostgreSQL
1. Что такое база данных?
База данных – это совокупность данных, хранящихся и извлекаемых в цифровом виде из удалённой или локальной компьютерной системы.
2. Что такое СУБД?
СУБД расшифровывается как Система Управления Базами Данных. СУБД – это системное программное обеспечение, ответственное за создание, поиск, обновление базы данных и управление ею. Она гарантирует, что наши данные организованы и легкодоступны, выступая в качестве интерфейса между базой данных и её конечными пользователями.
3. Что такое Реляционная СУБД? В чём заключается её отличие от СУБД?
РСУБД расшифровывается как Реляционная Система Управления Базами Данных. Ключевое отличие здесь, по сравнению с СУБД, заключается в том, что РСУБД хранит данные в виде набора таблиц, и между общими полями этих таблиц могут существовать отношения. Большинство современных систем управления базами данных, таких как MySQL, Microsoft SQL Server, Oracle, IBM DB2 и Amazon Redshift, основаны на РСУБД.
4. Что такое SQL?
SQL расшифровывается как язык структурированных запросов. Это стандартный язык для РСУБД. Он особенно полезен при обработке организованных данных, состоящих из сущностей (переменных) и отношений между различными сущностями данных.
5. В чём разница между SQL и MySQL?
SQL – это стандартный язык для извлечения структурированных баз данных и управления ими. Напротив, MySQL – это система управления реляционными базами данных, подобная SQL Server, Oracle или IBM DB2, которые используется для управления базами данных SQL.
6. Что такое таблицы и поля?
Таблица – это организованный набор данных, хранящихся в виде строк и столбцов. Столбцы могут быть классифицированы как вертикальные поля, а строки – как горизонтальные. Поля – это колонки в таблице, которые предназначены для хранения какой-либо информации.
7. Что такое ограничения в SQL?
Ограничения используются для указания правил, касающихся данных в таблице. Они могут быть применены к одному или нескольким полям в таблице SQL во время создания таблицы или после создания с помощью команды ALTER TABLE. Ограничениями являются:
- NOT NULL – ограничивает вставку нулевого значения в столбец.
- CHECK – проверяет, что все значения в поле удовлетворяют условие.
- DEFAULT – автоматически присваивает значение по умолчанию, если для поля не было указано значение.
- UNIQUE – гарантирует, что в поле будут вставлены уникальные значения.
- INDEX – индексирует поле, обеспечивая более быстрый поиск записей.
- PRIMARY KEY – уникально идентифицирует каждую запись в таблице.
- FOREIGN KEY – обеспечивает ссылочную целостность для записи в другой таблице.
8. Что такое PRIMARY KEY?
Ограничение PRIMARY KEY уникально идентифицирует каждую строку в таблице. Оно должно содержать UNIQUE значения и иметь неявное ограничение NOT NULL.
Таблица в SQL строго ограничена наличием одного и только одного PRIMARY KEY, который состоит из одного или нескольких полей (столбцов).
CREATE TABLE Students ( /* Create table with a single field as primary key */
ID INT NOT NULL
Name VARCHAR(255)
PRIMARY KEY (ID)
);
CREATE TABLE Students ( /* Create table with multiple fields as primary key */
ID INT NOT NULL
LastName VARCHAR(255)
FirstName VARCHAR(255) NOT NULL,
CONSTRAINT PK_Student
PRIMARY KEY (ID, FirstName)
);
ALTER TABLE Students /* Set a column as primary key */
ADD PRIMARY KEY (ID);
ALTER TABLE Students /* Set multiple columns as primary key */
ADD CONSTRAINT PK_Student /*Naming a Primary Key*/
PRIMARY KEY (ID, FirstName);9. Что такое UNIQUE?
Ограничение UNIQUE гарантирует, что все значения в столбце будут разными. Это обеспечивает уникальность столбца (ов) и помогает однозначно идентифицировать каждую строку. В отличие от PRIMARY KEY, для каждой таблицы может быть определено несколько уникальных ограничений. Синтаксис кода для UNIQUE очень похож на синтаксис PRIMARY KEY:
CREATE TABLE Students ( /* Create table with a single field as unique */
ID INT NOT NULL UNIQUE
Name VARCHAR(255)
);
CREATE TABLE Students ( /* Create table with multiple fields as unique */
ID INT NOT NULL
LastName VARCHAR(255)
FirstName VARCHAR(255) NOT NULL
CONSTRAINT PK_Student
UNIQUE (ID, FirstName)
);
ALTER TABLE Students /* Set a column as unique */
ADD UNIQUE (ID);
ALTER TABLE Students /* Set multiple columns as unique */
ADD CONSTRAINT PK_Student /* Naming a unique constraint */
UNIQUE (ID, FirstName);
10. What is a Foreign K10. Что такое FOREIGN KEY?
FOREIGN KEY состоит из одного поля или набора полей в таблице, которые ссылаются на PRIMARY KEY в другой таблице. Данное ограничение обеспечивает ссылочную целостность в отношении между двумя таблицами.
Таблица с FOREIGN KEY помечена как дочерняя таблица, а таблица, содержащая PRIMARY KEY, помечена как родительская таблица.
CREATE TABLE Students ( /* Create table with foreign key - Way 1 */
ID INT NOT NULL
Name VARCHAR(255)
LibraryID INT
PRIMARY KEY (ID)
FOREIGN KEY (Library_ID) REFERENCES Library(LibraryID)
);
CREATE TABLE Students ( /* Create table with foreign key - Way 2 */
ID INT NOT NULL PRIMARY KEY
Name VARCHAR(255)
LibraryID INT FOREIGN KEY (Library_ID) REFERENCES Library(LibraryID)
);
ALTER TABLE Students /* Add a new foreign key */
ADD FOREIGN KEY (LibraryID)
REFERENCES Library (LibraryID);11. Что такое объединение? Перечислите его различные типы.
SQL Join (объединение) используется для объединения записей (строк) из двух или более таблиц в базе данных SQL на основе связанного столбца между ними.

В SQL существует четыре различных типа соединений:
- (ВНУТРЕННЕЕ) СОЕДИНЕНИЕ: извлекает записи, которые имеют совпадающие значения в обеих таблицах, участвующих в соединении. Это широко используемое соединение для запросов.
SELECT *
FROM Table_A
JOIN Table_B;
SELECT *
FROM Table_A
INNER JOIN Table_B;- ЛЕВОЕ (ВНЕШНЕЕ) СОЕДИНЕНИЕ: извлекает все записи/строки из левой таблицы и соответствующие записи/строки из правой таблицы.
SELECT *
FROM Table_A A
LEFT JOIN Table_B B
ON A.col = B.col;- ПРАВОЕ (ВНЕШНЕЕ) СОЕДИНЕНИЕ: извлекает все записи/строки из правой таблицы и соответствующие записи/строки из левой таблицы.
SELECT *
FROM Table_A A
RIGHT JOIN Table_B B
ON A.col = B.col;- ПОЛНОЕ (ВНЕШНЕЕ) СОЕДИНЕНИЕ: извлекает все записи, в которых есть совпадение либо в левой, либо в правой таблице.
SELECT *
FROM Table_A A
FULL JOIN Table_B B
ON A.col = B.col;12. Что такое Self-Join?
Self-Join – это «самосоединение», объединение внутри одной таблицы. Оно используется тогда, когда у разных полей одной таблицы могут быть одинаковые значения.
SELECT A.emp_id AS "Emp_ID",A.emp_name AS "Employee",
B.emp_id AS "Sup_ID",B.emp_name AS "Supervisor"
FROM employee A, employee B
WHERE A.emp_sup = B.emp_id;13. Что такое перекрёстное соединение?
Во время перекрёстного соединения каждая строка одной таблицы соединяется с каждой строкой второй таблицы, давая тем самым в результате все возможные сочетания строк двух таблиц.
SELECT stu.name, sub.subject
FROM students AS stu
CROSS JOIN subjects AS sub;
14. Что такое индекс?
Индексы – это наборы уникальных значений для некоторой таблицы с соответствующими ссылками на данные. Они расположены в самой таблице и являются удобным внутренним механизмом системы SQL-сервера, с помощью которого осуществляется доступ к данным оптимальным способом.
CREATE INDEX index_name /* Create Index */
ON table_name (column_1, column_2);
DROP INDEX index_name; /* Drop Index */15. Какие существуют виды индексов?
Индексы бывают нескольких типов:
- Уникальный и неуникальный индекс:
Уникальные индексы – это индексы, которые помогают поддерживать целостность данных, гарантируя, что никакие две строки данных в таблице не имеют идентичных значений.
Неуникальные индексы не используются для применения ограничений к таблицам, с которыми они связаны. Вместо этого, неуникальные индексы используются исключительно для повышения производительности запросов за счет поддержания отсортированного порядка значений данных, которые часто используются.
- Кластеризованные и некластеризованные индексы
Кластеризованные индексы – это индексы, порядок строк в базе данных которых соответствует порядку строк в индексе. Вот почему в данной таблице может существовать только один кластеризованный индекс.
Некластеризованные индексы имеют структуру, отдельную от строк данных. В некластеризованном индексе содержатся значения ключа некластеризованного индекса, и каждая запись значения ключа содержит указатель на строку данных, содержащую значение ключа.
16. В чём разница между кластеризованными и некластеризованными индексами?
Основное различие между кластеризованным и некластеризованным индексом состоит в том, что кластеризованный индекс определяет, как данные хранятся в строках таблицы. С другой стороны, некластеризованный индекс хранит данные в одном месте, а индексы хранятся в другом месте.
17. Что такое целостность данных?
Целостность данных-это поддержание и обеспечение точности и согласованности данных на протяжении всего их жизненного цикла. Является критическим аспектом проектирования, внедрения и использования любой системы, которая хранит, обрабатывает или извлекает данные.
18. Что такое запросы в SQL?
SQL-запросы необходимы для работы с информацией из базы данных. Это может быть внесение, извлечение, сортировка, удаление и ряд других операций. При этом не указывается способ осуществления запрашиваемого действия.
SELECT fname, lname /* select query */
FROM myDb.students
WHERE student_id = 1;UPDATE myDB.students /* action query */
SET fname = 'Captain', lname = 'America'
WHERE student_id = 1;19. Что такое подзапросы в SQL?
Подзапрос – это запрос внутри другого запроса, также известный как вложенный запрос или внутренний запрос. Он используется для ограничения или улучшения данных, запрашиваемых основным запросом, тем самым ограничивая или улучшая выходные данные основного запроса. Например, здесь мы получаем контактную информацию для студентов, которые записались на предмет математики:
SELECT name, email, mob, address
FROM myDb.contacts
WHERE roll_no IN (
SELECT roll_no
FROM myDb.students
WHERE subject = 'Maths');Существует два типа подзапросов – коррелированные и некоррелированные.
20. Что такое оператор SELECT?
Оператор SELECT в SQL используется для выбора данных из базы данных. Возвращаемые данные сохраняются в таблице результатов, называемой результирующим набором.
21. Зачем нужны операторы UNION, MINUS и INTERSECT?
Оператор UNION отвечает за объединение строк из обоих подзапросов;
Оператор MINUS отвечает за вычитание результатов одного подзапроса из результатов второго подзапроса;
Оператор INTERSECT отвечает за пересечение строк из обоих подзапросов.
Перед выполнением любого из приведенных выше инструкций в SQL, необходимо выполнить определенные условия:
- Каждый оператор SELECT в предложении должен иметь одинаковое количество столбцов;
- Столбцы также должны иметь аналогичные типы данных;
- Столбцы в каждой инструкции SELECT обязательно должны иметь одинаковый порядок.
SELECT name FROM Students /* Fetch the union of queries */
UNION
SELECT name FROM Contacts;
SELECT name FROM Students /* Fetch the union of queries with duplicates*/
UNION ALL
SELECT name FROM Contacts;SELECT name FROM Students /* Fetch names from students */
MINUS /* that aren't present in contacts */
SELECT name FROM Contacts;SELECT name FROM Students /* Fetch names from students */
INTERSECT /* that are present in contacts as well */
SELECT name FROM Contacts;22. Что такое курсор?
Курсор в SQL – это область в памяти базы данных, которая предназначена для хранения последнего оператора SQL. Если текущий оператор – запрос к базе данных, в памяти сохраняется и строка данных запроса, называемая текущим значением, или текущей строкой курсора.
DECLARE @name VARCHAR(50) /* Declare All Required Variables */
DECLARE db_cursor CURSOR FOR /* Declare Cursor Name*/
SELECT name
FROM myDB.students
WHERE parent_name IN ('Sara', 'Ansh')
OPEN db_cursor /* Open cursor and Fetch data into @name */
FETCH next
FROM db_cursor
INTO @name
CLOSE db_cursor /* Close the cursor and deallocate the resources */
DEALLOCATE db_cursor23. Что такое сущности и отношения?
Сущность (entity) представляет тип объектов, которые должны храниться в базе данных. Каждая таблица в базе данных должна представлять одну сущность. Как правило, сущности соответствуют объектам из реального мира. У каждой сущности определяют набор атрибутов.
Отношения — это установленные связи между двумя или более таблицами. Отношения основаны на общих полях из более чем одной таблицы, часто связанных с первичными и иностранными ключами.

24. Перечислите различные типы связей в SQL.
- One-to-One – этот тип может быть определён как отношение между двумя таблицами, где каждая запись в одной таблице связана максимум с одной записью в другой таблице.
- One-to-Many & Many-to-One – это наиболее часто используемое отношение, когда запись в таблице связана с несколькими записями в другой таблице.
- Many-to-Many – этот тип используется в случаях, когда для определения отношения требуется несколько экземпляров с обеих сторон.
- Self-Referencing Relationships – этот тип используется, когда таблице необходимо определить связь с самой собой.
25. Что такое Alias в SQL?
Alias (псевдоним) — это имя, назначенное источнику данных в запросе при использовании выражения в качестве источника данных или для упрощения ввода и прочтения инструкции SQL. Такая возможность полезна, если имя источника данных слишком длинное или его трудно вводить. Псевдонимы могут быть использованы для переименования таблиц и колонок.
SELECT A.emp_name AS "Employee" /* Alias using AS keyword */
B.emp_name AS "Supervisor"
FROM employee A, employee B /* Alias without AS keyword */
WHERE A.emp_sup = B.emp_id;
Write an SQL statement to select all from table "Limited" with alias "Ltd".
26. What is a View?26. Что такое представление?
Представление в SQL – это виртуальная таблица, основанная на наборе результатов инструкции SQL. Представление содержит строки и столбцы, точно так же, как настоящая таблица. Поля в представлении – это поля из одной или нескольких реальных таблиц в базе данных.

27. Что такое нормализация?
Нормализация — это процесс организации данных в базе данных, включающий создание таблиц и установление отношений между ними в соответствии с правилами, которые обеспечивают защиту данных и делают базу данных более гибкой, устраняя избыточность и несогласованные зависимости.
28. Что такое денормализация?
Денормализация – это обратный процесс нормализации, при котором нормализованная схема преобразуется в схему, содержащую избыточную информацию. Производительность повышается за счет использования избыточности и обеспечения согласованности избыточных данных. Причиной выполнения денормализации являются накладные расходы, возникающие в процессоре запросов из-за чрезмерно нормализованной структуры.
29. Что такое подстановочные знаки?
Это специальные символы, которые нужны для замены каких-либо знаков в запросе. Они используются вместе с оператором LIKE, с помощью которого можно отфильтровать запрашиваемые данные.
30. Зачем нужны операторы TRUNCATE, DELETE и DROP?
TRUNCATE удаляет все строки из таблицы.
Команда DELETE используется для удаления одной или всех строк в таблице.
Команда DROP удаляет таблицу из базы данных. Все строки таблицы, индексы и привилегии удаляются.
31. В чём разница между операторами DROP и TRUNCATE?
Команда DROP удаляет таблицу из базы данных целиком, вместе со структурой. То есть после выполнения такой команды обратиться к удаленной таблице, например с помощью SELECT, будет уже нельзя. В свою очередь команда TRUNCATE удаляет не саму таблицу, а данные, которые эта таблица содержит.
32. В чём разница между операторами DELETE и TRUNCATE?
Операция DELETE блокирует каждую строку, а TRUNCATE — всю таблицу. Операция TRUNCATE не возвращает какого-то осмысленного значения (обычно возвращает 0) в отличие от DELETE, которая возвращает число удаленных строк. Также стоит заметить, что при использовании TRUNCATE, операцию удаления уже нельзя будет отменить.
33. Что такое агрегатные и скалярные функции?
Агрегатная функция выполняет вычисление над набором значений и возвращает одно значение. В табличной модели данных это значит, что функция берет ноль, одну или несколько строк для какой-то колонки и возвращает единственное значение. Для сравнения — скалярные функции принимают на вход одно значение и возвращают одно значение.
Примеры агрегатных функций:
- AVG() – Функция вычисляет среднее значение
- MAX() – Функция вычисляет элемент с максимальным значением
- MIN() – Функция вычисляет элемент с минимальным значением
- SUM() – Функция суммирует значения
Примеры скалярных функций:
- LEN() – Функция вычисляет общую длину поля
- MID() – Функция извлекает подстроки из набора строковых значений в таблице
- RAND() – Функция генерирует случайный набор чисел заданной длины
- NOW() – Функция возвращает текущую дату и время
34. Что такое определяемая пользователем функция?
Определяемая пользователем функция — это подпрограмма, которая принимает параметры, выполняет действие и возвращает результат в виде одного скалярного значения или результирующий набор.
35. Что такое OLTP?
OLTP – это транзакционные системы, то есть системы, ориентированные на быстрое добавление транзакций (операций) и, возможно, их изменения.

36. В чём различия между OLTP и OLAP?
OLTP-это система обработки транзакций, то есть она управляет приложениями, основанными на транзакциях, через Интернет. Например, системы OLTP отвечают за предоставление данных в хранилища данных. С другой стороны, OLAP-это система аналитической обработки. Это означает, что она отвечает на многомерные аналитические запросы, соответствующие финансовой отчетности, прогнозированию и т.д. Например, данные, доступные в хранилище данных, анализируются с помощью OLAP-системы.

37. Что такое сопоставление?
Сопоставление в SQL — это ряд правил, согласно которым сортируются и сравниваются данные. Эти правила определяют порядок сортировки символьных данных, в зависимости от регистра, надстрочных знаков (акцента), символьных типов Kana, ширины символов.
38. Что такое хранимая процедура?
Хранимая процедура – это объект базы данных, представляющий собой набор SQL-инструкций, который компилируется один раз и хранится на сервере. Хранимые процедуры очень похожи на обыкновенные процедуры языков высокого уровня, у них могут быть входные и выходные параметры и локальные переменные, в них могут производиться числовые вычисления и операции над символьными данными, результаты которых могут присваиваться переменным и параметрам.
DELIMITER $$
CREATE PROCEDURE FetchAllStudents()
BEGIN
SELECT * FROM myDB.students;
END $$
DELIMITER ;
39. Что такое рекурсивная хранимая процедура?
Рекурсивная хранимая процедура – это хранимая процедура, которая вызывает сама себя.
DELIMITER $$ /* Set a new delimiter => $$ */
CREATE PROCEDURE calctotal( /* Create the procedure */
IN number INT, /* Set Input and Ouput variables */
OUT total INT
) BEGIN
DECLARE score INT DEFAULT NULL; /* Set the default value => "score" */
SELECT awards FROM achievements /* Update "score" via SELECT query */
WHERE id = number INTO score;
IF score IS NULL THEN SET total = 0; /* Termination condition */
ELSE
CALL calctotal(number+1); /* Recursive call */
SET total = total + score; /* Action after recursion */
END IF;
END $$ /* End of procedure */
DELIMITER ; /* Reset the delimiter */
40. How to create empty tables with th40. Как создать пустые таблицы с той же структурой, что и у другой таблицы?
Создание пустых таблиц с одинаковой структурой может быть выполнено путём извлечения записей из одной таблицы в новую таблицу с помощью оператора INTO, установив при этом значение WHERE для всех записей равным false. Следовательно, SQL подготавливает новую таблицу с повторяющейся структурой для приема извлечённых записей, но поскольку никакие записи не извлекаются из-за действия предложения WHERE, в новую таблицу ничего не вставляется.
SELECT * INTO Students_copy
FROM Students WHERE 1 = 2;41. Что такое сопоставление шаблонов в SQL?
Сопоставление шаблонов SQL позволяет искать шаблоны в данных, если вы не знаете точное слово или фразу, которую ищете. Этот тип SQL – запроса использует подстановочные знаки для соответствия шаблону, а не точное его указание. Например, вы можете использовать подстановочный знак “C%” для соответствия любой строке, начинающейся с заглавной С .
SELECT *
FROM students
WHERE first_name LIKE 'K%'Вопросы для собеседования по PostgreSQL
42. Что такое PostgreSQL?
PostgreSQL — это реляционная база данных с открытым кодом, которая поддерживается в течение 30 лет разработки и является одной из наиболее известных среди всех существующих реляционных баз данных.
43. Как определять индексы в PostgreSQL?
Индексы – это встроенные функции в PostgreSQL, которые используются запросами для более эффективного выполнения поиска по таблице в базе данных. Предположим, что у вас есть таблица с тысячами записей, и у вас есть приведённый ниже запрос, согласно которому только несколько записей могут удовлетворять условию, тогда потребуется много времени для поиска и возврата тех строк, которые соответствуют этому условию. Это, несомненно, неэффективно для системы, имеющей дело с огромными данными. Теперь, если бы у этой системы был индекс столбца, в котором мы применяем поиск, она могла бы использовать эффективный метод для определения совпадающих строк, пройдя всего несколько уровней. Это называется индексацией.
Select * from some_table where table_col=12044. Как изменить тип данных столбца?
Это можно сделать с помощью инструкции ALTER TABLE, как показано ниже:
ALTER TABLE tname
ALTER COLUMN col_name [SET DATA] TYPE new_data_type;45. Какая команда используется для создания базы данных в PostgreSQL?
Первым шагом использования PostgreSQL является создание базы данных. Это делается с помощью команды createdb, как показано ниже: createdb db_name
CREATE DATABASE46. Как запустить, перезапустить или остановить сервер PostgreSQL?
Чтобы запустить сервер PostgreSQL, мы используем:
service postgresql startЧтобы перезапустить сервер PostgreSQL, мы используем:
service postgresql restartЧтобы остановить сервер PostgreSQL, мы используем:
service postgresql stop47. Что такое секционирование таблицы в PostgreSQL?
Секционированием данных называется разбиение одной большой логической таблицы на несколько меньших физических секций.
48. Что такое токен в PostgreSQL?
Токеном в PostgreSQL может являться ключевое слово, идентификатор, литерал, константа, идентификатор в кавычках, либо любой символ, обладающий отличительной индивидуальностью. Они могут быть разделены пробелом, новой строкой или табуляцией. Если токены являются ключевыми словами, то обычно это команды с полезными значениями. Токены известны как строительные блоки любого кода PostgreSQL
49. В чём важность оператора TRUNCATE?
Оператор TRUNCATE TABLE name_of_table эффективно и быстро удаляет данные из таблицы.
Оператор TRUNCATE также может быть использован для сброса значений столбцов идентификаторов вместе с очисткой данных, как показано ниже:
TRUNCATE TABLE name_of_table
RESTART IDENTITY;50. Какова максимальная ёмкость таблицы в PostgreSQL?
Максимальный размер таблицы PostgreSQL может составлять 32 ТБ.
51. Что такое последовательность?
Последовательность представляет собой объект, используемый для автоматического формирования чисел для различных целей, например для ключей.
52. Что такое строковые константы в PostgreSQL?
Строковые константы представляют собой последовательности символов, заключенные в одинарные кавычки. Они используются при вставке данных или обновлении символов в базе данных.
Существуют специальные строковые константы, которые указаны в долларах. Синтаксис: $tag$<string_constant>$tag$ Тег в константе необязателен, и когда мы не указываем тег, константа называется строковым литералом с двойным долларом.
53. Как можно получить список всех баз данных в PostgreSQL?
Это можно сделать с помощью команды l ( обратная слеш, за которым следует строчная буква L).
54. Как удалить базу данных в PostgreSQL?
Это можно сделать с помощью команды DROP DATABASE, как показано ниже:
DROP DATABASE database_name;Если база данных была удалена успешно, то будет показано следующее сообщение:
DROP DATABASE55. Что такое ACID?
Это свойства транзакции базы данных, которые используются для обеспечения достоверности данных в случае ошибок и сбоев.
56. Можете ли вы объяснить архитектуру PostgreSQL?
Архитектура PostgreSQL соответствует модели клиент-сервер.
Серверная часть состоит из диспетчера фоновых процессов, обработчика запросов, утилит и общего пространства памяти, которые работают вместе для создания экземпляра PostgreSQL, имеющего доступ к данным. Клиентское приложение выполняет задачу подключения к этому экземпляру и запрашивает обработку данных у служб. Клиентом может быть либо GUI (графический пользовательский интерфейс), либо веб-приложение. Наиболее часто используемым клиентом для PostgreSQL является pgAdmin.

57. Что вы понимаете под управлением параллелизмом нескольких версий?
Под управлением параллелизмом подразумевают различные техники, которые используются для сохранения целостности базы данных, когда несколько пользователей обновляют строки одновременно. Неверный параллелизм может привести к проблемам, таким как чтение фантомных данных, чтение недействительных данных и неповторяемые чтения.
58. Зачем нужна команда enable-debug?
Команда enable-debug используется для включения компиляции всех библиотек и приложений. Когда она включено, системные процессы затрудняются и, как правило, увеличивают размер двоичного файла. Следовательно, не рекомендуется использовать её в производственной среде. Чаще всего она используется разработчиками для отладки ошибок в своих скриптах и помогает им выявлять проблемы.
59. Какие существуют операторы в PostgreSQL?
Операторы PostgreSQL включают в себя арифметические операторы, операторы сравнения, логические операторы и побитовые операторы.
60. Что вы можете сказать о WAL (ведение журнала с опережением записи)?
Ведение журнала с опережением записи (WAL)-это стандартный метод обеспечения целостности данных. Подробное описание можно найти в большинстве (если не во всех) книг об обработке транзакций. Вкратце, центральная концепция WAL заключается в том, что изменения в файлах данных (где находятся таблицы и индексы) должны быть записаны только после того, как эти изменения были зарегистрированы, то есть после того, как записи журнала, описывающие изменения, были сброшены в постоянное хранилище.
61. В чем заключается основной недостаток удаления данных из существующей таблицы с помощью команды DROP TABLE?
Хотя команда DROP TABLE позволяет полностью удалить данные из существующей таблицы, у не` есть недостаток — она удаляет полную структуру таблицы из базы данных. Из-за этого нам нужно заново создать таблицу для хранения данных.
62. Как выполнить сопоставление без учёта регистра с использованием регулярных выражений в PostgreSQL?
Чтобы выполнить сопоставления без учета регистра с использованием регулярного выражения, мы можем использовать выражение POSIX (~*) из операторов сопоставления с образцом. Например:
'interviewbit' ~* '.*INTervIewBit.*'63. Как сделать резервную копию базы данных в PostgreSQL?
Мы можем достичь этого, используя инструмент pg_dump для сброса всего содержимого объекта в базе данных в один файл. Вот несколько шагов:
Шаг 1: Перейдите в папку bin по пути установки PostgreSQL.
C:>cd C:Program FilesPostgreSQL10.0binШаг 2: Запустите программу pg_dump, чтобы перенести дамп данных в папку .tar, как показано ниже:
pg_dump -U postgres -W -F t sample_data > C:Usersadminpgbackupsample_data.tarДамп базы данных будет сохранен в файле sample_data.tar в указанном расположении.
64. Поддерживает ли PostgreSQL полнотекстовый поиск?
Полнотекстовый поиск – это метод поиска одного документа или коллекции документов, хранящихся на компьютере, в полнотекстовой базе данных. В основном он поддерживается в продвинутых системах баз данных, таких как SOLR или ElasticSearch. Тем не менее, эта функция присутствует, но довольно проста в PostgreSQL.
65. Что такое параллельные запросы в PostgreSQL?
Параллельные запросы в PostgreSQL имеют возможность использовать более одного ядра процессора для каждого запроса.В параллельных запросах оптимизатор разбивает задачи запроса на более мелкие части и распределяет каждую задачу по нескольким ядрам процессора.

66. В чём разница между commit и checkpoint?
Действие commit обеспечивает сохранение согласованности данных транзакции и завершает текущую транзакцию в разделе. Commit добавляет в журнал новую запись, описывающую фиксацию в памяти. Checkpoint используется для записи всех изменений, которые были зафиксированы на диске, вплоть до SCN, которые будут храниться в заголовках файлов данных и файлах управления.
Заключение
SQL – это язык для работы с базой данных. Он обладает обширными и надёжными возможностями для создания различных объектов базы данных и управления ими с помощью таких команд, как CREATE, ALTER, DROP и т.д., А также загрузки объектов базы данных с помощью таких команд, как INSERT. Он также предоставляет опции для манипулирования данными с помощью таких команд, как DELETE, TRUNCATE, а ещё обеспечивает эффективное извлечение данных с помощью команд курсора, таких как FETCH, SELECT и т.д. Существует множество команд, которые предоставляют программисту большой объем контроля для эффективного взаимодействия с базой данных, не тратя впустую много ресурсов. Популярность SQL выросла настолько, что почти каждый программист полагается на него для реализации функций хранения данных в своих приложениях, что делает SQL полезным языком для изучения. Изучение этого даёт разработчику преимущество в понимании структур данных, используемых для хранения данных организации, и обеспечивает дополнительный уровень контроля и углубленного понимания приложения.
PostgreSQL, в свою очередь, являющаяся системой баз данных с открытым исходным кодом, обладающая чрезвычайно надежной и сложной поддержкой ACID, индексацией и транзакцией, завоевала широкую популярность среди сообщества разработчиков.
Просмотры: 3 418